and How To Fix Them.
I’ve seen many trends in SEO over the years. First there was voracious link profile building and keyword stuffing, but Google quickly took control of these techniques by penalising unnatural content and paid inbound links. It fascinates me that there are still companies out there touting paid for link-building as a legitimate SEO tactic. I know the benefits of naturally earned high domain authority backlinks, and I have probably triggered quite a few people with that statement, so I will just leave this from the Webmasters here..
Then for a while c_ontent was king_, and everyone was obsessing over long-form articles and writing towards character count goals.
In the last couple of years, the field of UX has become much more intertwined with SEO as softer engagement metrics come into focus. User first .
It’s no wonder then that tech hygiene often gets overlooked, with some of the best-known household brands failing to get even the basics right. Add into the mix the natural evolution of a website’s taxonomy and URL inventory over the years, alongside a lack of skills or budget to perform efficient SEO auditing, and you end up with a recipe for disaster. You may not see it coming, and it’s easy to put it to the back of your mind as you concentrate on getting the performance metrics in line with your KPIs, but one day you will begin to suffer loss of rankings and subsequent loss of traffic. Tech hygiene fixes tend to snowball out of control if left for too long, and what was once a quick fix becomes a massive retrospective issue. A bit of housekeeping now will pay dividends in the future.
So what are the most common tech hygiene issues we see on websites? Here are my top three, and their solutions.
1) Don’t Crawl Me Baby.
Robots.txt is a great way of managing crawl budget in sites with a lot of URL inventory. Asking search engines not to crawl large parts of your website is a great way to ensure that the core, important URLs are crawled, indexed and ranked. It makes your good stuff discoverable and puts the right results page entries in front of potential visitors. It is also great for keeping a development site out of the index altogether and is often used by website developers for this purpose.
So what is wrong with this picture here?

This is a robots.txt file I came across recently for a site that was not indexing at all. When this happens, my first candidates for auditing are always the robots.txt file and the directives. In this case I found a robots.txt file that was disallowing all User Agents from crawling any of the pages on the site.
* is a wildcard that denotes all User Agents, so that would be Google Bot and Bing Bot, my crawler tool and anything else that can crawl a site.
Disallow is the directive to the User Agents for what not to crawl. In this case, the forward slash / is telling crawlers not to crawl anything on the site. This is most likely a hang-over from when it was in development, and that forward slash needs to be removed to allow all User Agents access to the site (or another appropriate syntax). This is how it should look:-
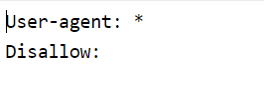
Simply removing that rogue character will solve a lot of this website’s issues with indexing (along with sitemap citations and a little help from Search Console).
2) Links, Links and More Links.
I mentioned the link building thing above, and internal linking seems to be another tactic that has been over-used to try and get better rankings. It’s a bit like keyword stuffing; the anchor text is a great indicator of target page content and I have seen many businesses with a patchwork of links and site-wide links, mistakenly believing that this will give them better potential to broadcast for a keyword or their brand term (dependent on the type of anchor used).
This isn’t how internal linking works though, and what you actually do by implementing this kind of internal profile is dilute your potential to broadcast. If you link everything, you have no hierarchy and no way of indicating reciprocal or logical relationships between pages. Think about your crawl budget. If a crawler doesn’t know where to go next it will end up crawling irrelevant links until the crawl budget is exhausted, leaving more important content out of the index.
Some site-wide links, such as those in the footer, are inevitable and won’t necessarily damage your ability to rank.
3) Beauty Over Functionality.
A H1 is pretty important right? H1 tags tell both search engines and users what the contents of a page is about. A well optimised H1, used alongside the meta title and parsable structured data, is a trifecta of keyword ranking potential.
So would it surprise you to know I have seen a fair few websites with no H1 tags at all??!!
Because of the relationship between the headers and the user interface itself, H1 tags often get incorrectly implemented or not implemented at all in favour of having a preferred font or font size.
This is a massive missed opportunity. There is no point in your website being pretty if it isn’t discoverable. Users are ultimately never going to end up seeing that interface.
My final advice on common SEO mistakes would be this; get your website audited annually by a professional technical SEO (there are different types of SEO). I may be biased but we will understand things outside of the data produced by a crawl, such as a relationship between a canonical, a redirect, and it’s indexability status. SEO is a holistic enterprise.
My top SEO Resources:
-Mobile SERPs pixel width and character count tool http://www.mobileserps.com/
-Screaming Frog, the most powerful auditing tool (in my opinion) and every SEOs best friend. The free version is a great place to start. The paid version is my can’t live without https://www.screamingfrog.co.uk/seo-spider/
-URL Profiler, for really getting to the bones of your content https://urlprofiler.com/